Unit Testing the Undeterministic: A Framework for Eval-Driven Development
February 5, 2026 • You cannot fix what you cannot measure. Moving beyond "vibes" in agent deployment.
Traditional software engineering gave us the luxury of deterministic outcomes. Sum `2` and `2`, reliably get `4`. Anything else is a bug. But working with LLMs throws you headfirst into probabilistic chaos. If your experimental agent confidently states "The answer is exactly 4" on Tuesday, yet casually shrugs out "It's roughly four" by Friday, what do you do? Are you tracking a critical bug or just dismissing it as model temperature?
Here at Learnastra Academy, we teach our students a controversial premise: the most profound risk destroying AI adoption isn't spontaneous hallucination. It's subtle, creeping Regression. We stumbled over this landmine ourselves while iterating on an internal legal-analysis agent. One seemingly brilliant prompt tweak drastically improved the bot's "friendliness." But three silent days later, we caught it spontaneously inventing fictitious case law. It completely derailed our confidence. Why didn't our safety nets catch it? Because we were running critical tests purely on "vibes" rather than rigid metrics.
Establishing Your Golden Dataset
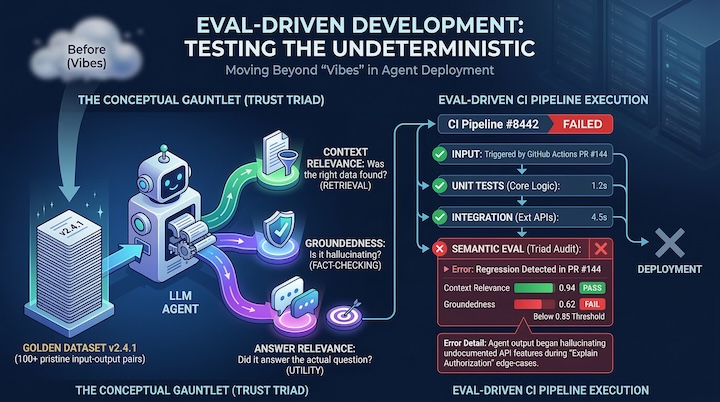
Trying to evaluate an agent without absolute context is a fool's errand. You desperately need a grounded source of "Truth." Whenever we spin up a new agent at KRKB, our prevailing strategy is enforcing a "Golden Dataset"—a tightly curated registry of 100+ pristine input and perfect expected output pairs covering the widest possible range of user intents.
This dataset isn't just a suggestion; it forms an unavoidable, rigid checkpoint. Absolutely zero codebase changes, system prompt adjustments, or temperature tweaks go into production until the agent survives this specific gauntlet.
You cannot just read an agent's output and say "looks good." You have to mechanically unbundle its logic against your Golden Dataset into three distinct scoring vectors:
-
1Context Relevance: Does the retrieval strictly locate applicable documentation, or does the semantic search blindly pull in 5 irrelevant paragraphs because they shared a keyword?
-
2Groundedness: Force the model to prove its work. Does the output rely entirely on the facts injected into the prompt, or does the LLM try to "be helpful" and stray into hallucinated fluff?
-
3Answer Relevance: Despite all technical constraints, does the resulting snippet directly address the user’s actual root query in a helpful manner?
The Counterintuitive Secret: The most reliable automated grader we found for this wasn't some complex Python rule engine. It was simply using a hyper-powerful model like Gemini 2.5 Pro to aggressively audit the homework of our smaller, cheaper operational agents.
Tracking Persistent Drift (The Silent Killer)
Here is a painful reality about generative AI: all models inevitably drift. An upstream update quietly hits OpenAI or Anthropic's servers, and overnight your hyper-tuned financial agent starts outputting poetic, unhelpful gibberish. That is exactly why an Eval-Driven pipeline is run completely autonomously via GitHub Actions against your dataset, matching regressions day over day.
If a seemingly harmless prompt update suddenly drags your "Tone Consistency Score" down below the safety threshold, klaxons start sounding in Slack. Taking this approach violently drags the chaotic, magical art of AI prompting back into the realm of structured, measurable software engineering. Instead of telling your lead engineer, "I changed the prompt and it just feels snappier," you can definitively point to the analytics and declare: "Our Legal dataset accuracy rose by 4.2% while the Math fallback took zero collateral damage. Merge the PR."
Elevating LLM nuance to a hard build failure guarantees that creeping hallucinations can never automatically reach users. If the "Groundedness" score drops, the pull request cannot be merged. Automation is the only shield against the silent deterioration of generative agents.
Vibes are Seductive Technical Debt
We say it internally all the time: Vibes don't scale. If you aren't actively measuring your agent's performance against a rigid, immutable baseline, you are knowingly deploying technical debt masquerading as a feature update. Eval-Driven Development is how Learnastra survived the chaos of AI in production, and frankly, it's the only way to build autonomous agents that don't silently degrade over time.